🚀 Enhancing Product Search with AI: My Internship Experience
During my internship as a Machine Learning Engineer at a fast‑paced e‑commerce startup, I worked on building a semantic search and recommendation system to improve product discovery in a large catalog.
🎯 Objective
The primary objective of my internship project was to enhance product search and retrieval using AI.
What We Set Out to Accomplish
🧠 Understand User Intent
Go beyond simple keyword matching to understand what users really want.
🔍 Semantic Retrieval
Retrieve semantically relevant products from a large catalog using embeddings.
📊 Smart Reranking
Rerank results to present the most meaningful items first.
By combining machine learning, vector embeddings, and LLM‑based reranking, we aimed to create a system that significantly improved user search experience.
🏗️ Design
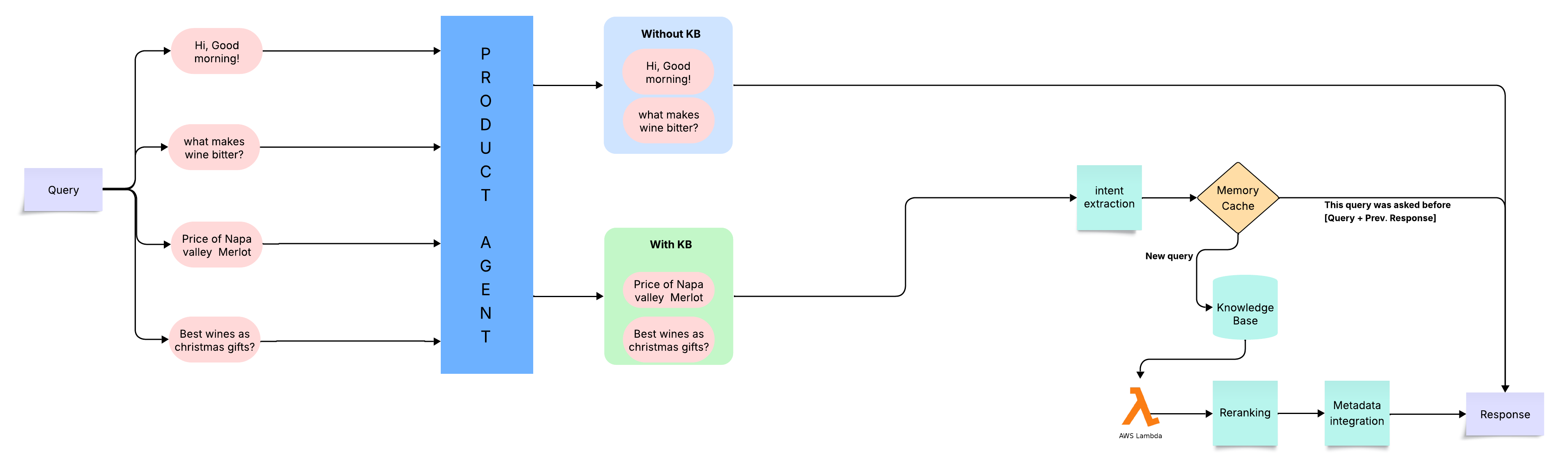
System architecture showing the complete AI‑powered search pipeline
🎭 1. Intent Classification
Purpose: Categorize incoming queries to guide downstream processing.
Query Types:
- 🛍️ Recommendation → “Suggest a fruity red wine”
- ℹ️ Informational → “What is a Pinot Noir?”
- 💬 Conversational → “I need a wine for dinner tonight”
Impact: Guides retrieval and reranking logic for better results.
🔢 2. Vector‑Based Retrieval
Core Technology: Semantic embeddings + vector similarity search
- Embedded all product attributes into a semantic vector space using sentence transformers
- Retrieved top candidate products using cosine similarity on Pinecone
Why This Works: Captures meaning and context, not just keyword matches.
🎯 3. Reranking Layer
Refinement Stage: LLM‑powered contextual reranking
- Applied LLM‑powered reranking (via Cohere Reranker) to refine the top results
- Focused on contextual relevance to the query
Result: Dramatically improved relevance of final search results.
🧹 4. Duplicate Filtering
Quality Control: Ensure clean, diverse results
- Used Levenshtein distance and semantic checks to remove near‑duplicate products
- Delivered cleaner, more diverse search results
☁️ 5. Deployment
Serverless Architecture: Scalable, cost‑effective deployment
- Deployed as a serverless pipeline using AWS Lambda, integrating Pinecone and third‑party APIs for reranking
- Designed for low‑latency response in a real‑time UI
📊 Data Processing
The data processing workflow was critical to enable semantic search:
📦 Product Embeddings
- Curated titles, descriptions, and attributes for thousands of products
- Generated dense embeddings with a pre‑trained transformer
🔍 Query Pre‑processing
- Normalized, tokenized, and embedded user queries in the same vector space
- Enabled direct semantic similarity comparisons between queries and products
✨ Filtering & Cleaning
- Applied post‑processing to remove repetitive or near‑identical results
- Optimized embeddings for efficient vector search in Pinecone
⚡ Optimization
Performance optimization ensured a smooth user experience:
- Latency Reduction: Streamlined API calls, cutting end‑to‑end response from ~2 min ➜ < 30 s.
- Prompt Engineering: Tuned LLM prompts for contextual reranking.
- Deduplication Logic: Combined string and semantic similarity scores to prevent duplicates.
📈 Evaluation
- Custom Dataset: ~250 diverse queries for regression testing.
- Manual Review: Visual inspection of top results with team feedback.
- Embedding Similarity: CLIP‑based scores to evaluate alignment of images and queries.
🎯 Key Takeaways
This project delivered a full end‑to‑end ML pipeline—from data processing and semantic retrieval to latency optimization and live evaluation—strengthening my skills in machine learning engineering, MLOps, and semantic search.